Durante este verano hemos estado trabajando en la migración del portal del Museo Reina Sofía, en el que continuamente estamos aplicando mejoras, a un nuevo proveedor de hosting. El ecosistema hardware y software del museo se compone de una implantación bastante compleja de Drupal 7 como CMS y Apache Solr como indexador y buscador de contenidos.
A nivel de infraestructura hardware los diferentes portales del museo están desplegados en una infraestructura virtualizada en alta disponibilidad que incluye dos servidores frontales que incorporan Varnish como proxy inverso para cachear peticiones, apache con php5 como servidor de aplicaciones y memcache para el cacheo en memoria de Drupal. A nivel de base de datos disponemos de un cluster maestro-esclavo de Mysql en servidores separados que alojan también el servicio de búsquedas basado en Solr 4 en una implantación clusterizada.
El portal principal del Museo recibe bastante tráfico (incluido un rastreo continuo por parte de indexadores) que hace que cuidemos bastante el rendimiento del portal y su disponibilidad.

El problema
En el proceso de puesta en producción de la nueva infraestructura nos encontramos con un problema difícil de solucionar. Esporádicamente algunas páginas de edición de contenidos en el CMS tenían tiempos de renderizado de más de 20 segundos (llegando incluso a 40 segundos algunas de ellas), lo que dificultaba el trabajo de los editores de contenidos que continuamente están alimentando el portal.
El problema se podía demostrar fácilmente activando el módulo devel y configurándolo para que mostrase el tiempo de ejecución de página y las consultas a base de datos realizadas.
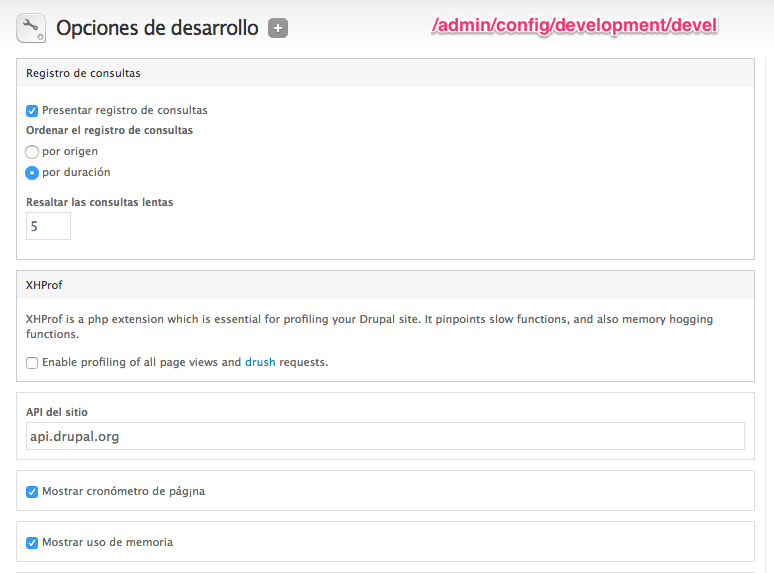
Una ejecución de una de las páginas en cuestión hacía aflorar el problema. Después de bastantes pruebas, identificamos que normalmente ocurría cuando el sistema tenía las caches de Drupal vacías (aunque ocurría esporádicamente también). La primera petición a una página de edición de un contenido devolvía tiempos de ejecución superiores a 20 segundos, la segunda petición ya daba tiempos normales (entre 1 o 2 segundos de ejecución total).
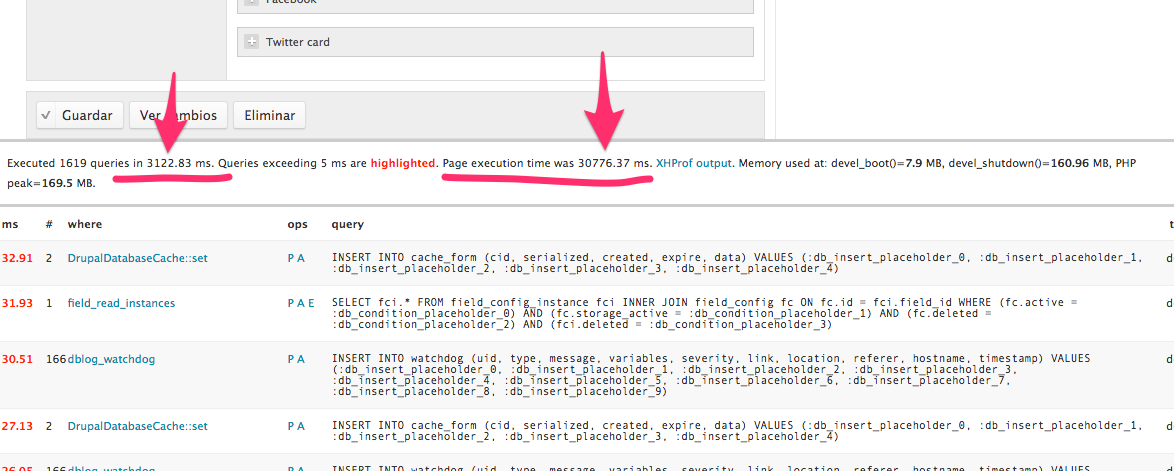
Después de verificar mil veces toda la configuración de los nuevos servidores, no encontrábamos el problema, además estábamos prácticamente seguros de que era un problema de configuración o potencia de los nuevos servidores, ya que en la infraestructura anterior el problema no ocurría nunca y podíamos compararlas en condiciones similares.
Primera tentativa de solución: ¡más hierro! Aunque habíamos verificado que los tiempos de ejecución de la capa de base de datos eran similares a los de la infraestructura anterior, no me resistía a pensar que el principal cuello de botella de Drupal era el responsable de todo esto, o sea, más potencia a la base de datos, más memoria a los frontales y más CPU a toda la infraestructura. ¿Mejora? ¡Ninguna! Además el log del módulo devel ya lo decía: tiempo de ejecución de llamadas a BD 3 segundos, tiempo de ejecución de página 30 segundos (en este caso la llamada a base de datos es muy lenta porque teníamos activado todo el debug ya para intentar localizar el problema).
Segundo intento: ¡simplificación! Estaba claro que teníamos algún bloqueo esporádico con algún recurso externo, lo primero en lo que pensé fue en alguna configuración errónea de memcache o apache solr de los que depende la infraestructura para muchas peticiones. Fuimos quitando uno a uno cada uno de estos servicios, pero el problema seguía ahí.
Tercer intento: ¡profiling! Teniendo en cuenta que esto solo lo reproducíamos en los servidores de producción y que estaban ya en activo, me resistía a meter una herramienta que afectase al servicio, pero visto que no encontrábamos el problema, nos decantamos por sacar uno de los frontales de nuestro balanceador y utilizar una herramienta de profiling para intentar localizar el problema. Vamos con los detalles.
Profiling al rescate
Para los que no lo sepáis, una herramienta de profiling permite analizar al detalle qué está ocurriendo con una petición a nivel de tiempos de ejecución y consumo de memoria de cada función por la que pasa la petición al servidor. Existen muchas herramientas de profiling, para este caso me decanté por usar la herramienta desarrollada por facebook: xhprof ya que su integración con Drupal 7 está muy documentada.
No me alargaré en la instalación de la herramienta y su integración con Drupal 7, es algo bastante sencillo de realizar con muchas referencias en internet (yo seguí este post). Una vez que todo está configurado (incluida la integración con el módulo devel de Drupal), cada petición al servidor mostrará un link en el pie de página que permite acceder al informe de profiling de dicha página.

Realmente lo difícil con xhprof es saber interpretar los resultados, así que intentaré aportar mi granito de arena con cómo he analizado los informes para dar con el problema, realmente estamos ante un caso sencillo pero muy común.
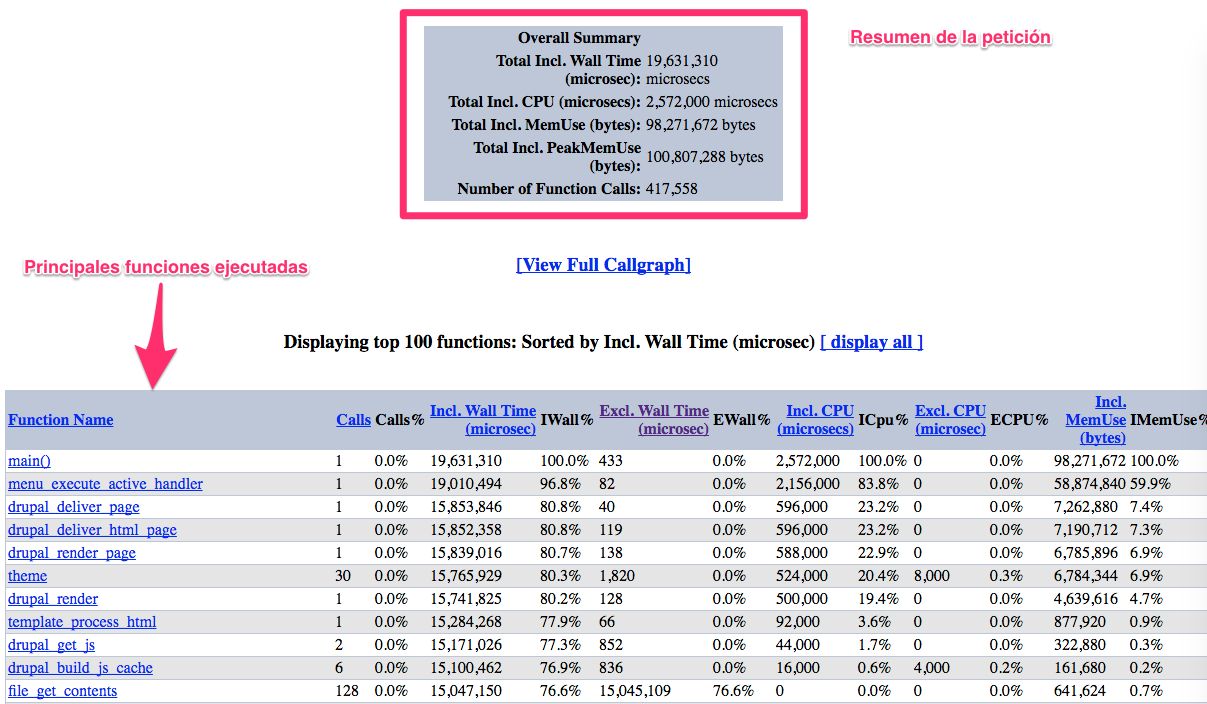
El informe de xhprof nada más abrirlo muestra 2 zonas:
- Resumen de la petición: en este resumen podemos ver los grandes números de la petición analizada y nuestro problema. 19,6 segundos de ejecución de los cuales solo 2,5 son de consumo de CPU.
- Principales funciones ejecutadas: en esta tabla se muestran las principales funciones ejecutadas con posibilidad de ordenarlas por diferentes criterios.
La forma de usar este informe consiste en trabajar sobre la ordenación de esta tabla de funciones, ya que cada columna representa un concepto diferente. Inicialmente la tabla viene ordenada por la columna «Included Wall Time»), que muestra el tiempo total de ejecución de cada función, incluido el tiempo de la propia función. Esta visualización normalmente no dice grandes cosas, al menos si buscamos funciones que estén consumiendo mucho tiempo de ejecución (como es mi caso). Lo único que vemos es que la función main ocupa el 100 % del tiempo de ejecución (ya que es la que engloba toda la petición de Drupal).
Realmente para detectar el problema, en este caso de alto consumo de tiempo de ejecución, ordenaremos la tabla por «Excl. Wall Time», que muestra el tiempo de ejecución de una función excluyendo el tiempo de ejecución de las funciones hijas. Y ¡voilà! aquí esta el culpable:
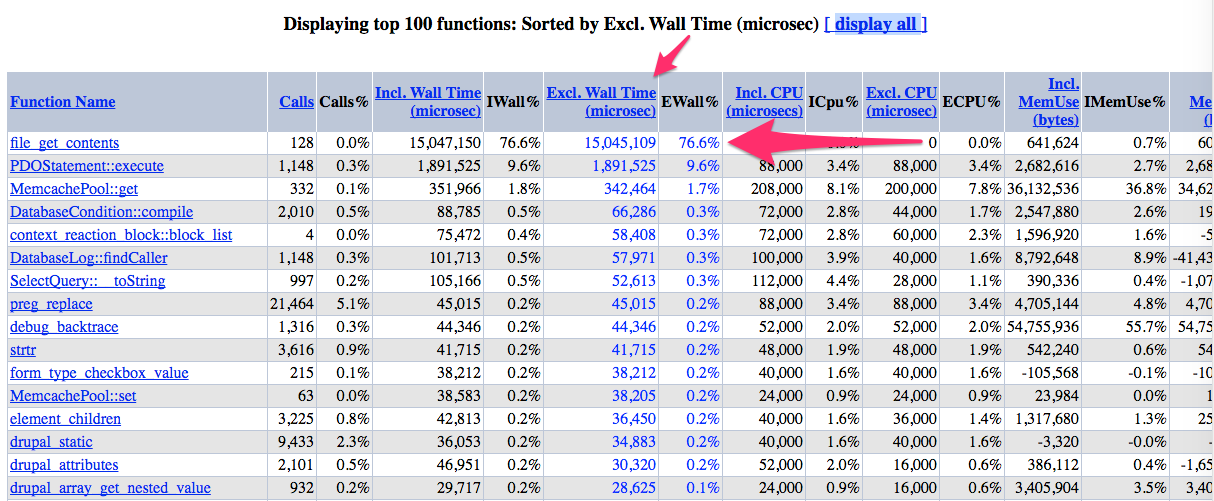
En este informe tenemos un resultado concluyente, la función de php file_get_contents está ocupando 15 segundos de tiempo de ejecución, y se ejecuta 128 veces. Pero… y ahora ¿cómo encuentro yo cuál de las llamadas a esa función está dando problemas? (en nuestra implantación de Drupal 7 se usa más de 100 veces). Aquí esta lo bueno, podemos navegar por el informe para obtener más información sobre esta función pulsando sobre el nombre de la misma:
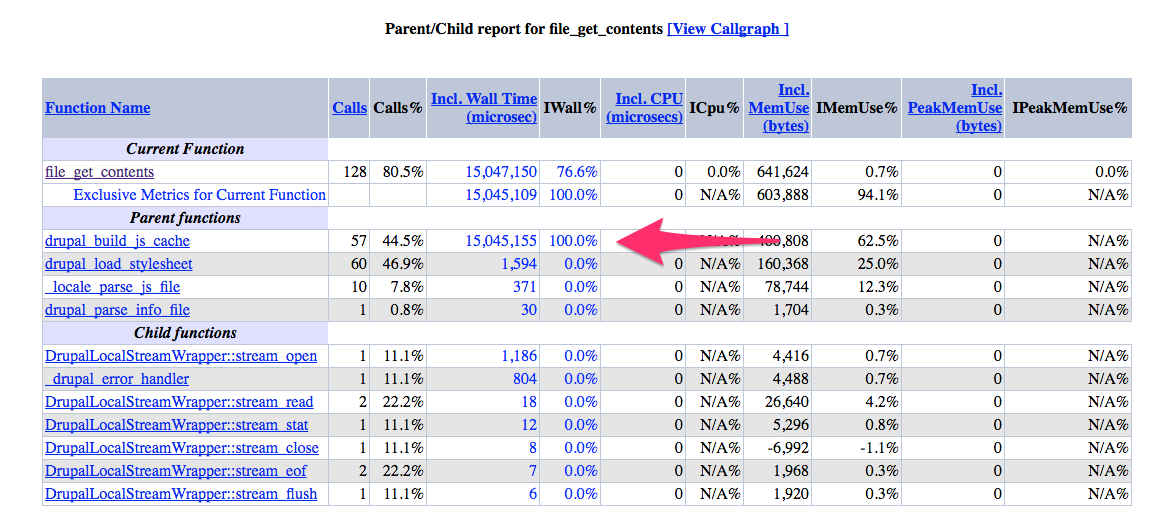
Ya empiezo a ver la luz, ahora sí tengo un culpable que puedo diseccionar. En esta visualización podemos observar que la función drupal_build_js_cache es la que está consumiendo todo el tiempo de ejecución. Y analizando el código de dicha función, vemos que es la que se encarga de «empaquetar» todos los ficheros JS de la aplicación y generar un fichero con el agregado para optimizar el rendimiento del frontend. Y como el problema está en la llamada a file_get_contents de dicho fichero, parece que tenemos un problema con alguna lectura de alguno de esos ficheros en el servidor. ¿Pero cuál?, ¿será tema de permisos?, ¿será que el acceso a disco en los nuevos servidores es superlento? Bueno, no queda otra que debugear esta función, el problema es que como solo nos pasa en producción no podemos meter un debugger interactivo como xdebug, así que nos tendremos que servir de un simple log como este:
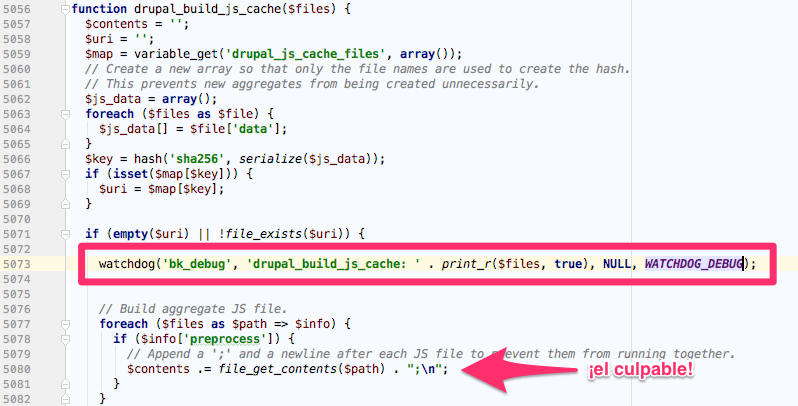
Y revisando el log generado por una petición que ha presentado el problema vemos lo siguiente:
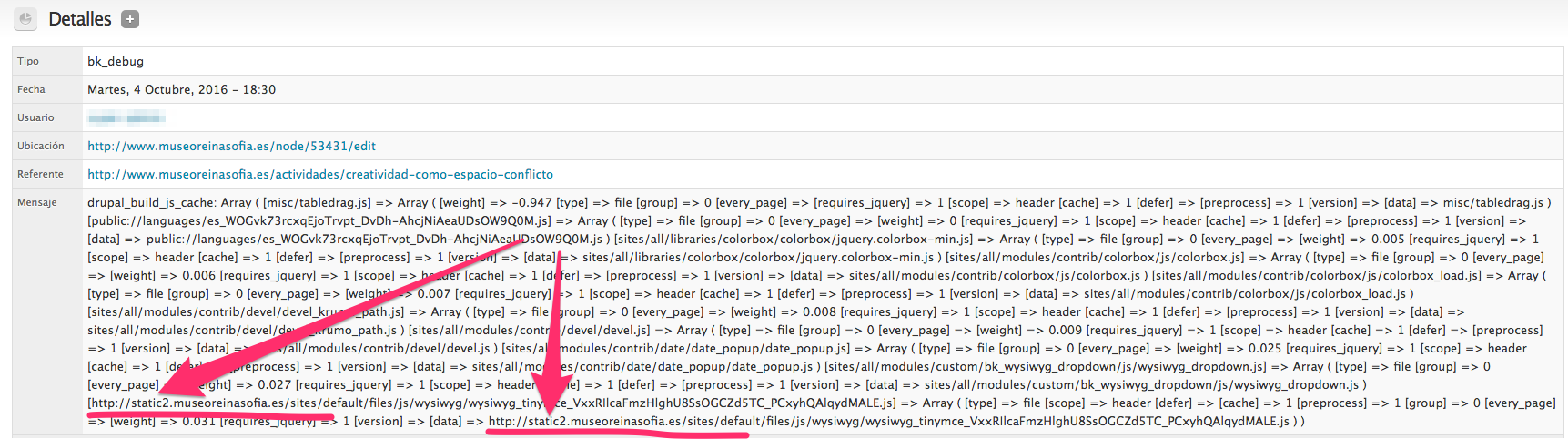
¡2 ficheros JS que se están intentando empaquetar provienen no de un fichero local, sino de una llamada http!. En este caso la llamada http va contra nuestra propia máquina en un subdominio donde estamos sirviendo los ficheros estáticos para optimizar el rendimiento del frontend. ¿Y cuál es el problema? Este:

Resulta que los propios servidores no son capaces de acceder por http a sí mismos. Esto es lo que provoca el bloqueo y los tiempos de espera hasta que la función file_get_contents da un timeout.
La solución
Que los servidores resuelvan esa petición. Lección aprendida después de dedicar multitud de horas y recursos a intentar revisar el tunning del servidor, un profiling puede dar pistas de un problema puntual de rendimiento y ahorrar muchos dolores de cabeza como los que he tenido el último mes.
¡Gracias, xhprof!

