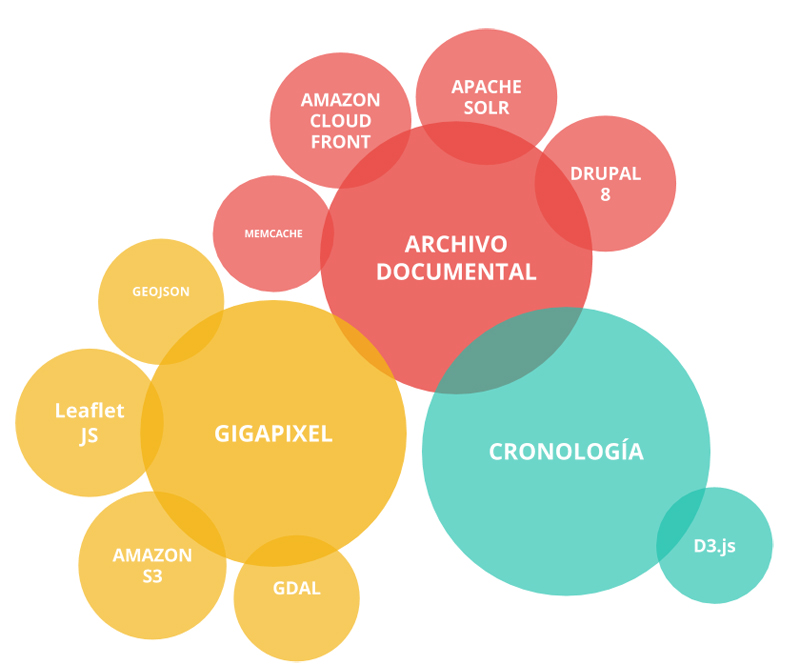
Repensar Guernica es un proyecto web que se compone de 3 desarrollos independientes: Archivo documental, Gigapíxel y Cronología. Se trata de una investigación que recoge más de 2.000 documentos relacionados con el Guernica de Picasso. Dichos documentos pueden ser explorados por medio de dos vías: un buscador facetado y una interfaz interactiva de visualización de datos (cronología).
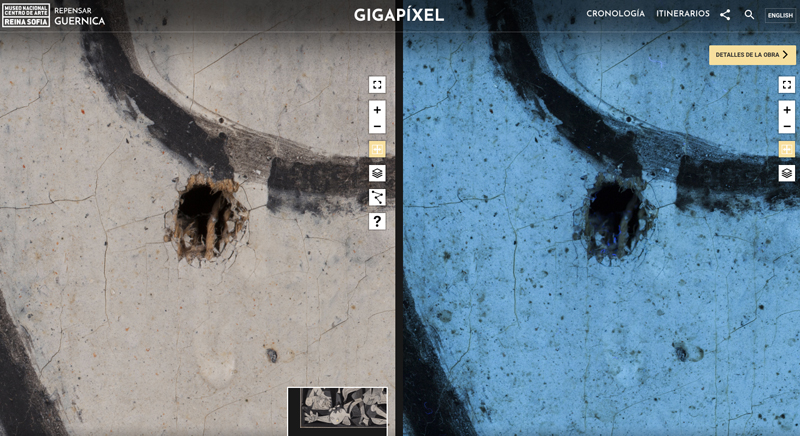
El proyecto, asimismo, incluye una aplicación que permite explorar el cuadro con un nivel de detalle muchísimo mayor que la percepción del ojo humano. Esto representa un hito tecnológico en sí mismo, gracias a que es la imagen más grande de una obra de arte jamás realizada. La combinación de una alta resolución con las dimensiones de la obra hace que el resultado sea una imagen de 690.000 píxeles por 311.000 píxeles que se puede consultar con un explorador de zoom. Todo ello a través del navegador web del ordenador, tablet o smartphone. Además, están disponibles las imágenes de alta resolución capturadas con luz visible, luz ultravioleta, luz infrarroja y radiografía con rayos X.
Ya hemos hablado de los objetivos del proyecto en nuestra web o la propia web del Museo Reina Sofía, en este post os vamos a contar los detalles más técnicos del proyecto.
Archivo documental: Drupal, un CMS para dominarlos a todos
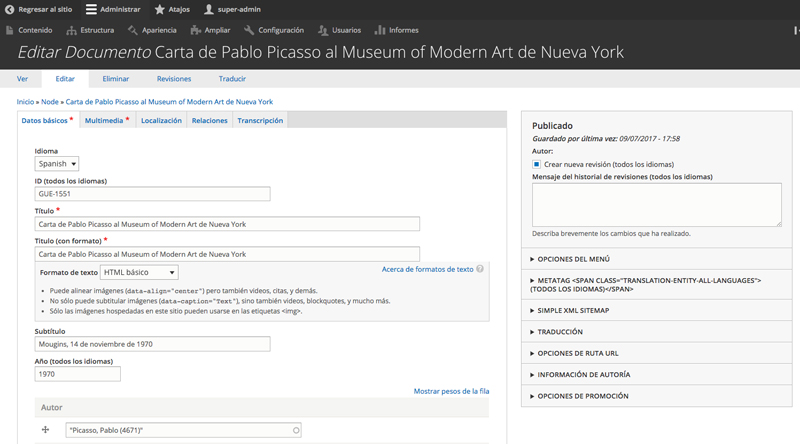
El núcleo de la arquitectura del proyecto es una implantación de Drupal 8 como gestor de contenidos. Funcionalmente necesitamos que los investigadores del Museo Reina Sofía puedan gestionar fácilmente todos los contenidos, permitiendo su clasificación en diferentes taxonomías e incorporando poco a poco material multimedia asociado a cada documento de la investigación. La elección de Drupal es una decisión continuista con la arquitectura general de todos los portales del Museo Reina Sofía, construidos usando Drupal 7, pero con el paso a Drupal 8 ganamos todas las ventajas de la última versión –ya hablamos de ello hace un tiempo-, aseguramos alargar su vida útil y favorecemos su mantenibilidad. Además, en este caso nos resulta muy útil, como veremos más adelante, la facilidad de integración con el sistema de búsquedas.
La implantación de en este proyecto se caracteriza por:
- Utiliza 5 tipos de contenido diferentes. Los principales son documento y relato.
- 10 taxonomías diferentes que permiten clasificar en diferentes dimensiones los documentos (autor, bibliografía, ubicación, protagonista, procedencia…).
- Un sistema de construcción de portadas y portadillas modular basado en el módulo paragraphs.
- Un sistema de gestión de activos multimedia que permite asociar de forma sencilla y flexible a los documentos imágenes en alta resolución, videos, audios…
Indexación y búsquedas
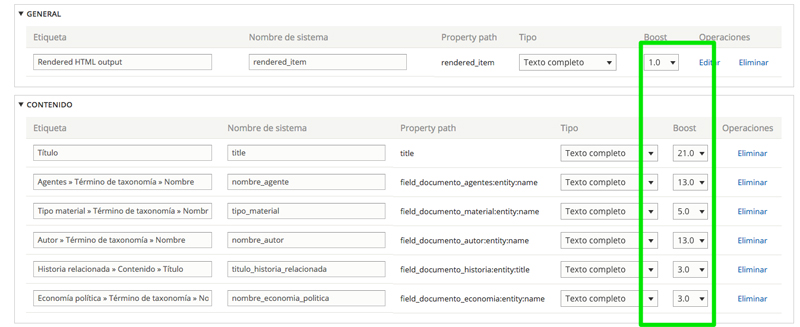
Alrededor de todo el archivo documental se ha construido un sistema de búsquedas facetadas basado en Apache Solr. Se trata de un producto Open Source de la Fundación Apache construido bajo tecnología Java que conocemos a fondo y con el que nos sentimos cómodos. La integración con Drupal la hemos realizado utilizando los módulos Search API y Facets.
Claves de la construcción de un buen buscador
Las claves de la construcción de un buen buscador se basan en:
- realizar una configuración personalizada de los campos a indexar y del peso a asignar a cada uno de dichos campos en el índice de solr
- realizar un análisis del modelo de datos del proyecto
- construir una jerarquía que permita asignar diferentes pesos a cada campo y entidad para ajustar el algoritmo que utiliza solr para determinar la relevancia de cada documento.
Tenemos ya bastante bagaje en la implantación de sistemas de búsqueda facetados, pero esta vez hemos querido dar una vuelta de tuerca más a la usabilidad de la interfaz.
-
- Jerarquización de facetas: Al abordar un proyecto en el que queremos exponer toda la potencia de filtrado posible para un público especializado (investigadores) hay que tener especial cuidado en la ubicación de las facetas, su ordenación y la interacción con las mismas cuando pueden tener cientos de resultados por los que filtrar, de lo contrario el sistema de facetas abrumará al usuario y lo hará inmanejable.
- Interacción con cada faceta: Por cada faceta disponible en un conjunto de resultados hemos construido un bloque que muestra los filtros con más ocurrencias, limitando a 10 elementos cada bloque y permitiendo al usuario desplegar un pop-up que permite realizar una búsqueda libre sobre las facetas con menos ocurrencias. Cada bloque de facetas va adaptando su contenido al conjunto de resultados mostrado en cada momento.

-
- Interacción con sistema de facetas en móvil: Hemos cuidado la interacción con el sistema de facetas. La versión responsive para pantallas pequeñas utiliza un sistema de plegados para mostrar los diferentes filtros. Así conseguimos centrar la atención del usuario en la interacción principal que es la búsqueda libre y el bloque de resultados, sin perder la posibilidad de refinar la búsqueda.
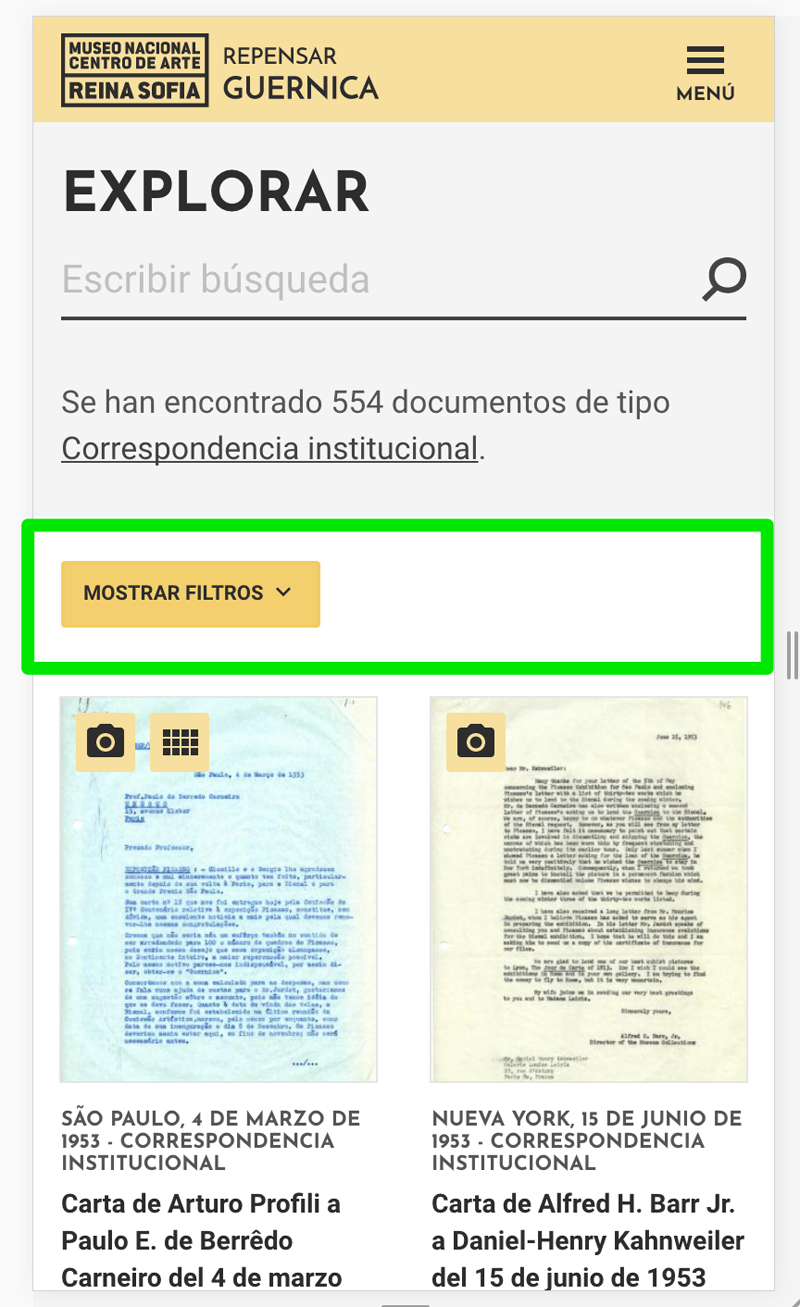
-
- Naturalización del resumen de los resultados de búsqueda: Un componente del que estamos especialmente orgullosos, en el que hemos puesto especial cariño para mejorar la experiencia de usuario:
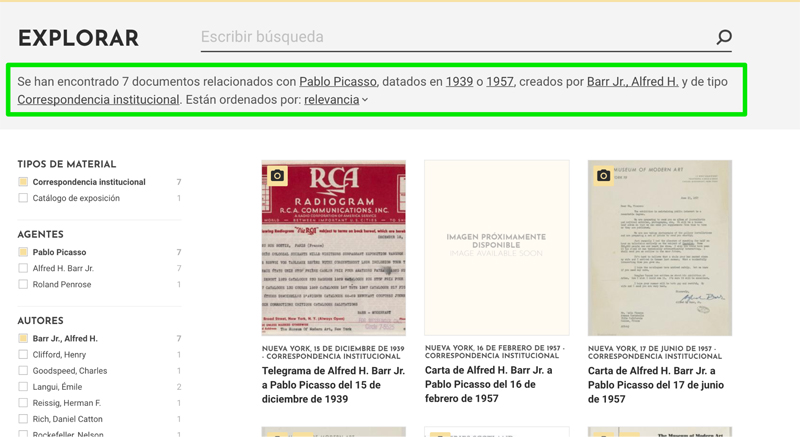
Hasta ahora siempre habíamos modelado este resumen de filtros aplicados como un conjunto de etiquetas que el usuario podía eliminar posteriormente. Pero esta vez hemos querido informar al usuario en un lenguaje natural, y además gramaticalmente correcto, como si le estuviésemos diciendo en persona qué es lo que hemos encontrado para su búsqueda. Técnicamente hemos tenido que implementar un nuevo Servicio en Drupal (basado en FacetsSummaryManager) que gestiona la renderización de dicho sumario de búsquedas.
SEO
La implicación de SEO en todos los procesos (conceptualización, AI y UX, diseño, maquetación, desarrollo y contenidos), sumado a las capacidades de Drupal, permite un buen posicionamiento onsite de la página web. La configuración básica SEO en Drupal 8 que hacemos y revisamos en todos nuestros proyectos pasa por utilizar:
-
-
- los módulos pathauto (para configurar la generación automática de pretty urls),
- metatag (generación automática de metainformación para SEO y SEM),
- y simple_sitemap (para la publicación de sitemaps XML en Google).
-
Gigapíxel de Repensar Guernica
El reto: construir una aplicación web que permitiese explorar hasta el más mínimo detalle del Guernica de Picasso. Como base teníamos el conjunto de imágenes que se obtuvieron durante el estudio realizado en 2012 “Viaje al interior del Guernica”. El origen de dicho estudio radica en la colocación de un automatismo robotizado y controlado por ordenador. El robot se desplazaba con una precisión de 25 micras delante de la obra captando imágenes y datos con gran precisión en diferentes canales: luz visible, infrarrojo multiespectral, ultravioleta, escáner en 3D y reflectancia espectral. El resultado es un conjunto de imágenes que componen la imagen a mayor tamaño (690.000 píxeles por 311.000 píxeles) de una obra de arte jamás captada.

Tratamiento de las imágenes
Un doble objetivo
Uno de los mayores problemas al que nos hemos enfrentado en el proyecto ha sido el doble objetivo de:
-
-
- disponer de un formato de la imagen del Guernica que fuese manejable por un navegador web,
- que a la vez requiriese una infraestructura de servidor que soportase picos de tráfico muy fuertes y no requiriese de una inversión en hardware muy alta.
-
El Departamento de Restauración del Museo Reina Sofía en colaboración con la Universidad Politécnica de Madrid ha estado trabajando durante años para procesar las imágenes obtenidas por el robot y convertirlas en una imagen útil para sus investigaciones. El resultado es una imagen georreferenciada alojada en un servidor GeoServer, tecnología que actualmente se está utilizando para la construcción de aplicaciones de mapas interactivos (al estilo de Google Maps). El problema con ese formato es que requiere de una infraestructura de servidores compleja y costosa para soportar el tráfico que esperamos.
La solución
Como solución, optamos por transformar las imágenes usadas por GeoJSON a una pirámide de imágenes estática. Concretamente a una pirámide de imágenes que fuera legible por la librería de generación de mapas online opensource más famosa, Leaflet.js. Para ello partiendo del mosaico de imágenes a mayor resolución (en el canal visible por ejemplo son 51.224 imágenes de 2.048 x 2.048 px), las procesamos usando las herramientas (concretamente gdal2tiles) que se utilizan para las operaciones con imágenes que se usan en este tipo de aplicaciones de mapas. Con ello generamos una pirámide compuesta por 12 niveles de profundidad y un total de 8.742.468 imágenes de 256×256 pixeles.
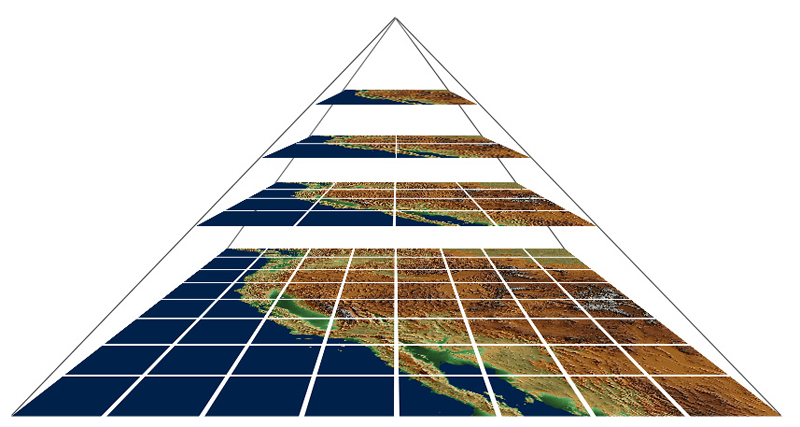
Los detalles del proceso
Algunos detalles del proceso para que os hagáis idea del volumen de datos procesado:
-
-
- Número de ficheros origen para canal visible: 51.224
- Número de ficheros generados para el canal visible: 8.742.468
- Tamaño en píxeles del nivel de zoom más profundo: 311.296 x 690.176 px.
- Volumen de datos del canal visible: 436 Gb.
- Tiempo de procesamiento para transformar la imagen en formato GeoJSON a Leaflet: 162 horas. ¡Casi 7 días para procesar una imagen! Y eso que utilizamos la infraestructura de servidores más potente de la que disponemos en Biko y que la optimizamos para operar de forma óptima con grandes volúmenes de pequeños ficheros en disco. Para obtener las imágenes de los 4 canales utilizados hemos tenido 1 mes trabajando nuestras máquinas a pleno rendimiento.
-
Si viéramos el mayor nivel de zoom en monitores uno al lado del otro, harían falta 180 metros de lado y 75 de alto (¡más de 100.000 monitores!).
Arquitectura de la aplicación Gigapíxel
A nivel técnico, la aplicación de Gigapíxel es un subproyecto totalmente independiente del resto del portal. Se trata de una Single Page Application construida usando exclusivamente HTML, JS y CSS. El núcleo de la aplicación está basado en la librería Leaflet.js, que es la responsable de manejar la pirámide de imágenes que hemos alojado en Amazon S3, dicha librería la hemos complementado con una serie de extensiones opensource y otras desarrolladas a medida por nosotros:
-
-
- Leaflet-hash: nos permite ir obteniendo urls con un código hash que permite reconstruir el estado de la aplicación, con el objetivo de poder compartir en redes sociales detalles peculiares de la imagen.
- Leaflet-minimap: Permite mostrar con una pequeña imagen donde se encuentra el zoom del usuario.
- Leaflet.sync: nos permite comparar 2 visualizaciones de la misma imagen. Aquí está otro de los retos técnicos que más quebraderos de cabeza nos ha dado. Las imágenes de las diferentes vistas no tienen la misma resolución y tamaño en pixels, por lo que hemos tenido que realizar operaciones de escalado y traslación para reposicionar ambas imágenes que nos han hecho recordar nuestras mayores pesadillas en clase de trigonometría…
-
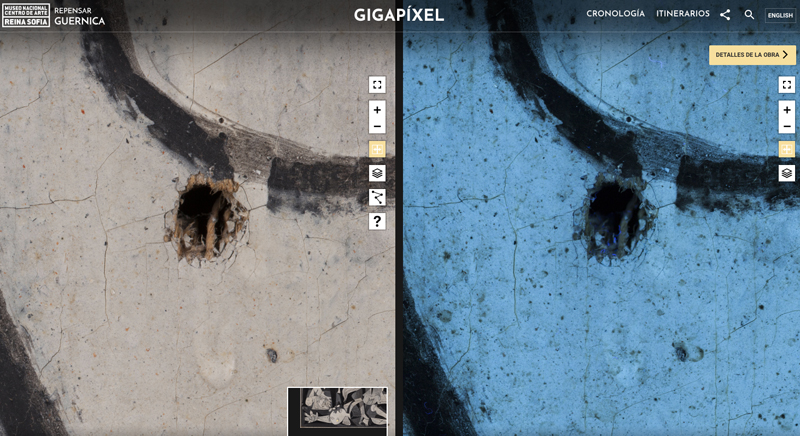
Visita el Gigapíxel de Repensar Guernica
Cronología del Guernica
Una forma distinta de explorar Repensar Guernica
La cronología es otra de las perlas del site Repensar Guernica. Se trata de es una herramienta de exploración del archivo documental del Guernica con un enfoque diferente al del buscador y en un rico formato de visualización de datos. La cronología es obra de Víctor San Vicente, nuestro okupa de Ningunaparte.
Aporta una visión contextual extra al usuario, ya que permite ubicar tan extensa documentación en un marco temporal, acompañado de una línea superior que nos marca hitos históricos a nivel mundial que influenciaron en la historia y viajes del cuadro.
La cronología muestra a lo largo de un eje temporal todos los documentos generados en torno al cuadro: fotografías, carteles, correspondencia, etc. Es una aplicación pensada para el descubrimiento y la inmersión.
De forma interactiva podemos filtrar estos contenidos por autor, tipo de documento, o exposiciones en las que estuvo presente la obra icónica de Picasso. La selección se nos muestra siempre en su marco temporal, de manera que podemos ver perfectamente el volumen de documentos que se han ido generando a lo largo de los diferentes hitos y momentos históricos del siglo XX-XXI.
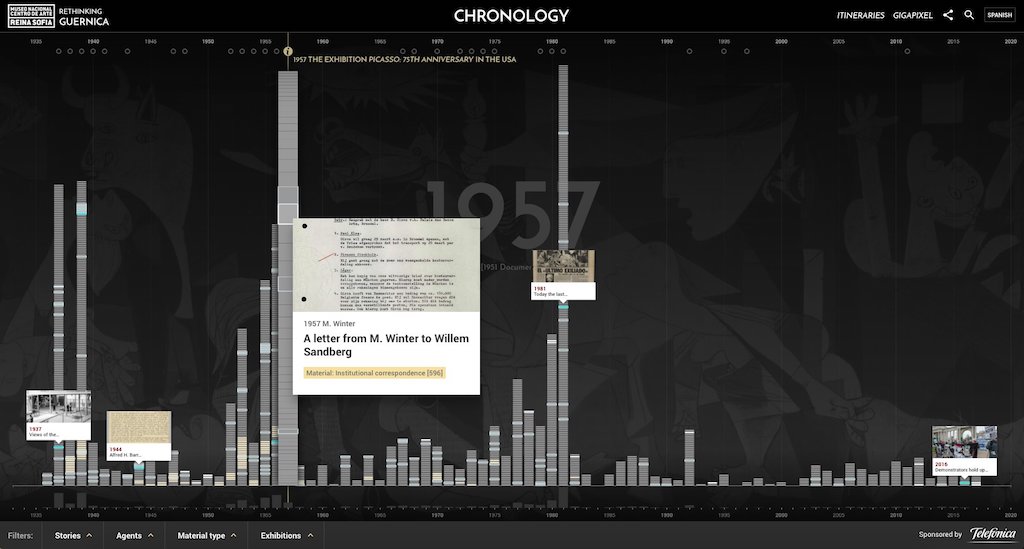
Visita la cronología de Repensar Guernica
La parte técnica de la cronología
Técnicamente está construida como una aplicación javascript utilizando la librería de visualización de datos D3.js (Data-driven Documents). Esta librería es uno de los más potentes instrumentos existentes para construir visualizaciones de datos, por su versatilidad y respeto de los estándares web encajaba perfectamente en el diseño del proyecto. La visualización de la información se muestra en forma de SVG dinámico, totalmente interactivo, que permite interactuar con los documentos.
La información necesaria para la aplicación se obtiene de los datos almacenados en Drupal que a través de una API son expuestos en formato TSV e interpretados dentro de D3.
Su experiencia de usuario
Gran parte del trabajo en esta visualización ha recaído en estudiar la UX para tener accesible casi 2.000 elementos interactivos simultáneamente en pantalla con sutiles refinamientos como:
- zooms en años de gran concentración de documentos,
- escalados automáticos de cada año mejorando la selección
- o la capacidad de hacer drag-and-drop para encontrar documentos similares.
La home, una presentación interactiva para conocer el Guernica
Un reto de storytelling: “Cómo contar con pocas palabras una gran historia”
El proyecto Repensar Guernica es extenso, profundo, riquísimo para investigadores. Pero en Biko teníamos una preocupación extra: ¿cómo logramos transmitir toda la fuerza de esta investigación al público general?, ¿cómo podemos generar interés sobre esta base documental inédita a personas que apenas conocen el Guernica de Picasso?
Queríamos dar un contexto amplio sobre cuestiones generales, pero desconocidas para muchos de nosotros: ¿cuándo pintó Picasso el Guernica?, ¿por qué?, ¿qué pasó con el cuadro desde que Picasso lo pintó hasta que llegó a España y por qué?
Mucha información, y una sola oportunidad para enganchar al usuario. Esta pieza fue una a las cuales dimos más vueltas; queríamos acertar. Y optamos por trabajar el storytelling con una navegación guiada en la que cuidamos cada detalle, cada frase, cada imagen.
El lugar de contar esta historia era la propia portada de la web Repensar Guernica. La solución radica en ir presentando en la home, de forma interactiva y muy guiada, una serie de textos acompañados con imágenes que aparecen a medida que el usuario va haciendo scroll.
Desarrollo de la intro de la home de Guernica
El desarrollo de este interactivo está basado en una aplicación javascript con animaciones CSS3 construido usando como base varias librerías javascript cada una con un ámbito de responsabilidad diferente:
- Fullpage.js: es la base para construir un conjunto de slides que ocupan la pantalla completa del navegador y coordina las transiciones entre los diferentes slides. Algo esencial para conseguir una narrativa fluida, que dé el tiempo justo al usuario para leer y sentirse dentro de la historia que queremos contarle.
- GreenSock: utilizada para construir escenas y animaciones encadenadas, que son las que lanzamos en determinados eventos controlados por Fullpage.js. Por ejemplo, cuando el usuario entra en un slide, lanzamos una animación que da una opacidad a la imagen de fondo, a los 0,5 segundos hacemos aparecer el texto principal con una traslación en el eje X, pasado 1 segundo hacemos aparecer el pie de foto, etc.
Visita la cronología de Repensar Guernica
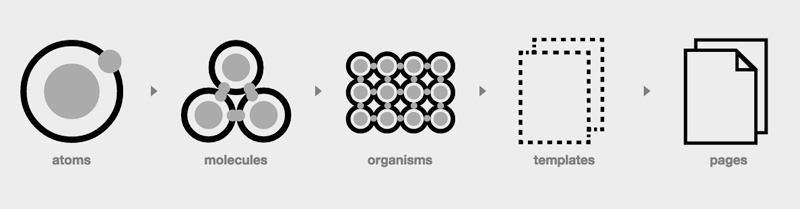
HTML por Componentes: Atomic Design
Para la construcción del HTML de todo el proyecto nos hemos basado en la metodología de diseño Atomic Design enfocada en la reutilización acumulativa de elementos modulares sencillos (componentes) para crear estructuras de información más complejas. Requiere de nuevas formas de pensar y trabajar. En lugar de diseñar páginas, diseñamos componentes.
Esta metodología nos fuerza a pensar en el sistema en su globalidad y no en cada página individualmente, y como resultado, hemos obtenido un catálogo de componentes HTML que reutilizamos constantemente para construir las páginas, lo cual nos da una mayor consistencia a nivel de experiencia de uso y gráfico.
Buenas prácticas para el código CSS
Necesitamos que nuestros estilos tengan la misma calidad que el código de back-end, para ello:
- Hemos usado el pseudolenguaje SASS para escribir nuestras hojas de estilo CSS, que nos permite escribir un código sin duplicidades, más fácilmente mantenible y evolucionable.
- El código SASS sigue una estricta guía de estilos de código con un conjunto de buenas prácticas.
- La organización de código sigue las normas de ITCSS que nos ayuda a organizar nuestros estilos en capas de especificidad y objetivos.
- Aplicamos la metodología BEM para conseguir una mayor semántica y cohesión en los nombres de los estilos de cada componente.
Implantado sobre los hombros de gigantes: Amazon AWS
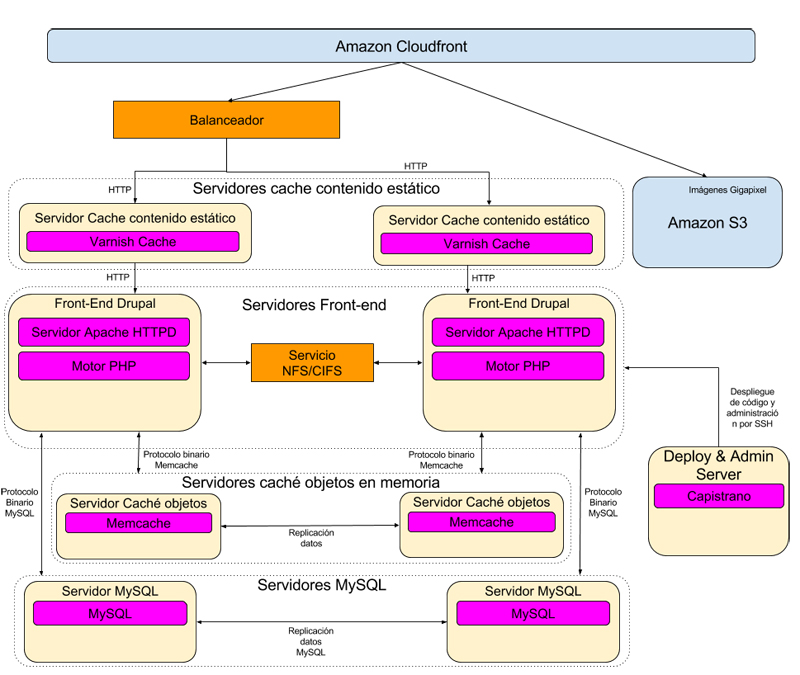
Otro de los aspectos críticos de un proyecto como este radica en el rendimiento y escalabilidad de la arquitectura. Al ser un proyecto con una fuerte difusión en medios generalistas de comunicación esperamos picos de tráfico importantes, por todo hemos tenido que reforzar la arquitectura del portal para protegernos de dichos picos de tráfico, la clave: Amazon Cloudfront.
Sobre la arquitectura de servidores que utilizamos para el hosting de los proyectos del Museo Reina Sofía hemos implementado una capa de CDN basada en Amazon Cloudfront integrándolo con Drupal utilizando el módulo CDN.
Además de una capa de CDN, el proyecto usa software específico para optimizar el rendimiento en la capa servidora: un cluster Varnish como proxy inverso de cacheo de archivos estáticos y código generado por Drupal, un cluster Memcache como cache en memoria para las operaciones de cacheo de bajo nivel de Drupal y un cluster SOLR para el sistema de indexación y búsquedas. Además todo el almacenamiento de ficheros estáticos relacionados con Gigapíxel está soportado por Amazon S3.
Repensar Guernica, un proyecto con pasión
Este proyecto ha sido una auténtica historia de amor para nuestro equipo. Con pasión, e incluso dolor en algunas ocasiones. Pero con un resultado del que tanto nuestro cliente el Museo Reina Sofía y nosotros ya estamos disfrutando.
Nos gusta hacer las cosas con cariño, y por eso queríamos contar con detalle el proyecto. También nos gusta mejorar, así que si tienes cualquier comentario o sugerencia, no dudes en enviarlo a oompas@biko2.com.


6 comentarios sobre “Qué hay detrás de Repensar Guernica”